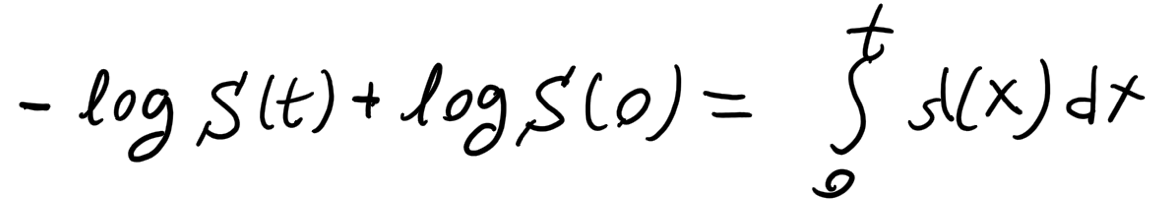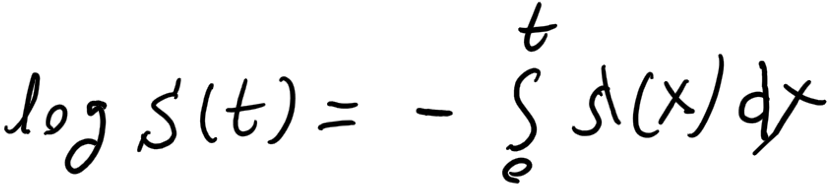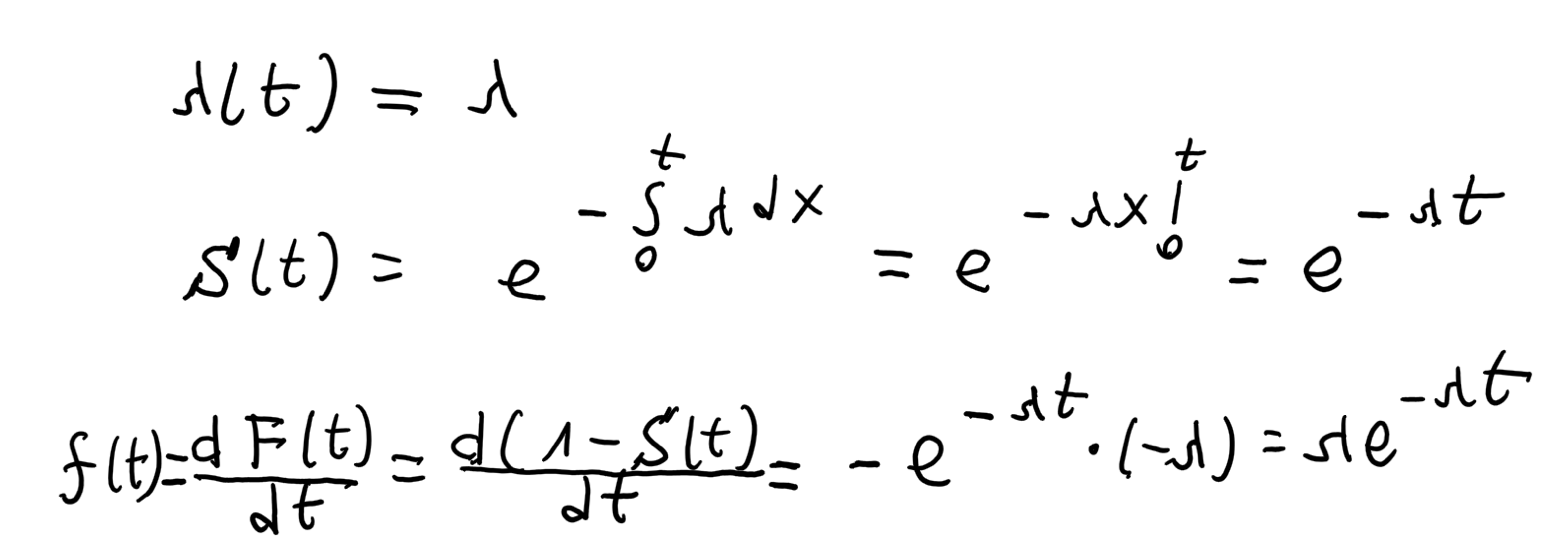Introduction
There are four fundamental elements in the Git Workflow.
Working Directory, Staging Area, Local Repository and Remote Repository.

If you consider a file in your Working Directory, it can be in three possible states.
- It can be staged. Which means the files with with the updated changes are marked to be committed to the local repository but not yet committed.
- It can be modified. Which means the files with the updated changes are not yet stored in the local repository.
- It can be committed. Which means that the changes you made to your file are safely stored in the local repository.
git addis a command used to add a file that is in the working directory to the staging area.git commitis a command used to add all files that are staged to the local repository.git pushis a command used to add all committed files in the local repository to the remote repository. So in the remote repository, all files and changes will be visible to anyone with access to the remote repository.git fetchis a command used to get files from the remote repository to the local repository but not into the working directory.git mergeis a command used to get the files from the local repository into the working directory.git pullis command used to get files from the remote repository directly into the working directory. It is equivalent to agit fetchand agit merge.
git --version

git config --global --list

Check your machine for existing SSH keys:
ls -al ~/.ssh
If you already have a SSH key, you can skip the next step of generating a new SSH key
Generating a new SSH key and adding it to the ssh-agent
ssh-keygen -t rsa -b 4096 -C "your_email@example.com"
When adding your SSH key to the agent, use the default macOS ssh-add command. Start the ssh-agent in the background:
Adding a new SSH key to your GitHub account
To add a new SSH key to your GitHub account, copy the SSH key to your clipboard:
pbcopy < ~/.ssh/id_rsa.pub

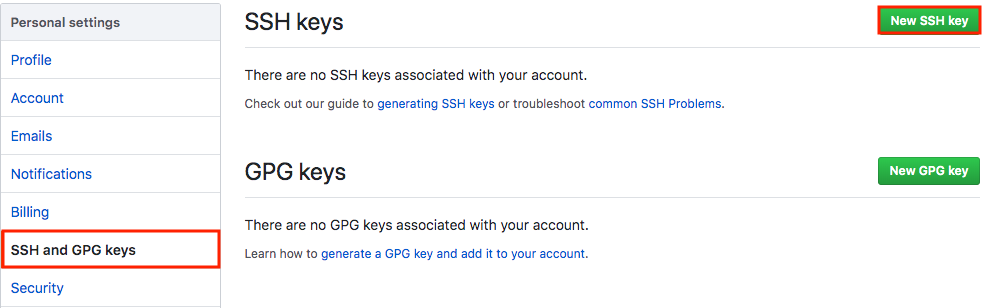
Copy the In the “Title” field, add a descriptive label for the new key. For example, if you’re using a personal Mac, you might call this key “Personal MacBook Air”.
Paste your key into the “Key” field.

After you’ve set up your SSH key and added it to your GitHub account, you can test your connection:
ssh -T git@github.com
Let’s Git
Create a new repository on GitHub. Follow this link.
Now, locate to the folder you want to place under git in your terminal.
echo "# testGit" >> README.md
Now to add the files to the git repository for commit:
git add .
git status

Now to commit files you added to your git repo:
git commit -m "First commit"

git status

Add a remote origin and Push:
Now each time you make changes in your files and save it, it won’t be automatically updated on GitHub. All the changes we made in the file are updated in the local repository.
To add a new remote, use the git remote add command on the terminal, in the directory your repository is stored at.
The git remote add command takes two arguments:
- A remote name, for example,
origin - A remote URL, for example,
https://github.com/user/repo.git
Now to update the changes to the master:
git remote add origin https://github.com/ofirsh/testGit.git
git remote -v

Now the git push command pushes the changes in your local repository up to the remote repository you specified as the origin.
git push -u origin master

And now if we go and check our https://github.com/ofirsh/testGit repository page on GitHub it should look something like this:

See the Changes you made to your file:
Once you start making changes on your files and you save them, the file won’t match the last version that was committed to git.
Let’s modify README.md to include the following text:

To see the changes you just made:
git diff

Markers for changes
--- a/README.md
+++ b/README.md
These lines are a legend that assigns symbols to each diff input source. In this case, changes from a/README.md are marked with a --- and the changes from b/README.md are marked with the +++ symbol.
Diff chunks
The remaining diff output is a list of diff ‘chunks’. A diff only displays the sections of the file that have changes. In our current example, we only have one chunk as we are working with a simple scenario. Chunks have their own granular output semantics.
Revert back to the last committed version to the Git Repo:
Now you can choose to revert back to the last committed version by entering:
git checkout .
View Commit History:
You can use the git log command to see the history of commit you made to your files:
$ git log

echo 'testGit #2' > README.md git add . git commit -m 'second commit' git push origin master

Pushing Changes to the Git Repo:
Now you can work on the files you want and commit to changes locally. If you want to push changes to that repository you either have to be added as a collaborator for the repository or you have create something known as pull request. Go and check out how to do one here and give me a pull request with your code file.
So to make sure that changes are reflected on my local copy of the repo:
git pull origin master
Two more useful command:
git fetch
git merge
In the simplest terms, git fetch followed by a git merge equals a git pull. But then why do these exist?
When you use git pull, Git tries to automatically do your work for you. It is context sensitive, so Git will merge any pulled commits into the branch you are currently working in. git pull automatically merges the commits without letting you review them first.
When you git fetch, Git gathers any commits from the target branch that do not exist in your current branch and stores them in your local repository. However, it does not merge them with your current branch. This is particularly useful if you need to keep your repository up to date, but are working on something that might break if you update your files. To integrate the commits into your master branch, you use git merge.
Pull Request
Pull requests let you tell others about changes you’ve pushed to a GitHub repository. Once a pull request is sent, interested parties can review the set of changes, discuss potential modifications, and even push follow-up commits if necessary.
null
Pull requests are GitHub’s way of modeling that you’ve made commits to a copy of a repository, and you’d like to have them incorporated in someone else’s copy. Usually the way this works is like so:
- Lady Ada publishes a repository of code to GitHub.
- Brennen uses Lady Ada’s repo, and decides to fix a bug or add a feature.
- Brennen forks the repo, which means copying it to his GitHub account, and clones that fork to his computer.
- Brennen changes his copy of the repo, makes commits, and pushes them up to GitHub.
- Brennen submits a pull request to the original repo, which includes a human-readable description of the changes.
- Lady Ada decides whether or not to merge the changes into her copy.
Creating a Pull Request
There are 2 main work flows when dealing with pull requests:
- Pull Request from a forked repository
- Pull Request from a branch within a repository
Here we are going to focus on 2.
Creating a Topical Branch
First, we will need to create a branch from the latest commit on master. Make sure your repository is up to date first using
git pull origin master

To create a branch, use git checkout -b <new-branch-name> [<base-branch-name>], where base-branch-name is optional and defaults to master. I’m going to create a new branch called pull-request-demo from the master branch and push it to github.
git checkout -b pull-request-demo

git status

git push origin pull-request-demo

Now you can see two branches:

and

make some changes to README.md:
echo "test git #3 pull-request-demo" >> README.md cat README.md


Commit the changes:
git add README.md git commit -m 'commit to pull-request-demo'

…and push your new commit back up to your copy of the repo on GitHub:
git push --set-upstream origin pull-request-demo

Back to the web interface:

You can press the “Compare”, and now you can create the pull request:

Go ahead and click the big green “Create Pull Request” button. You’ll get a form with space for a title and longer description:
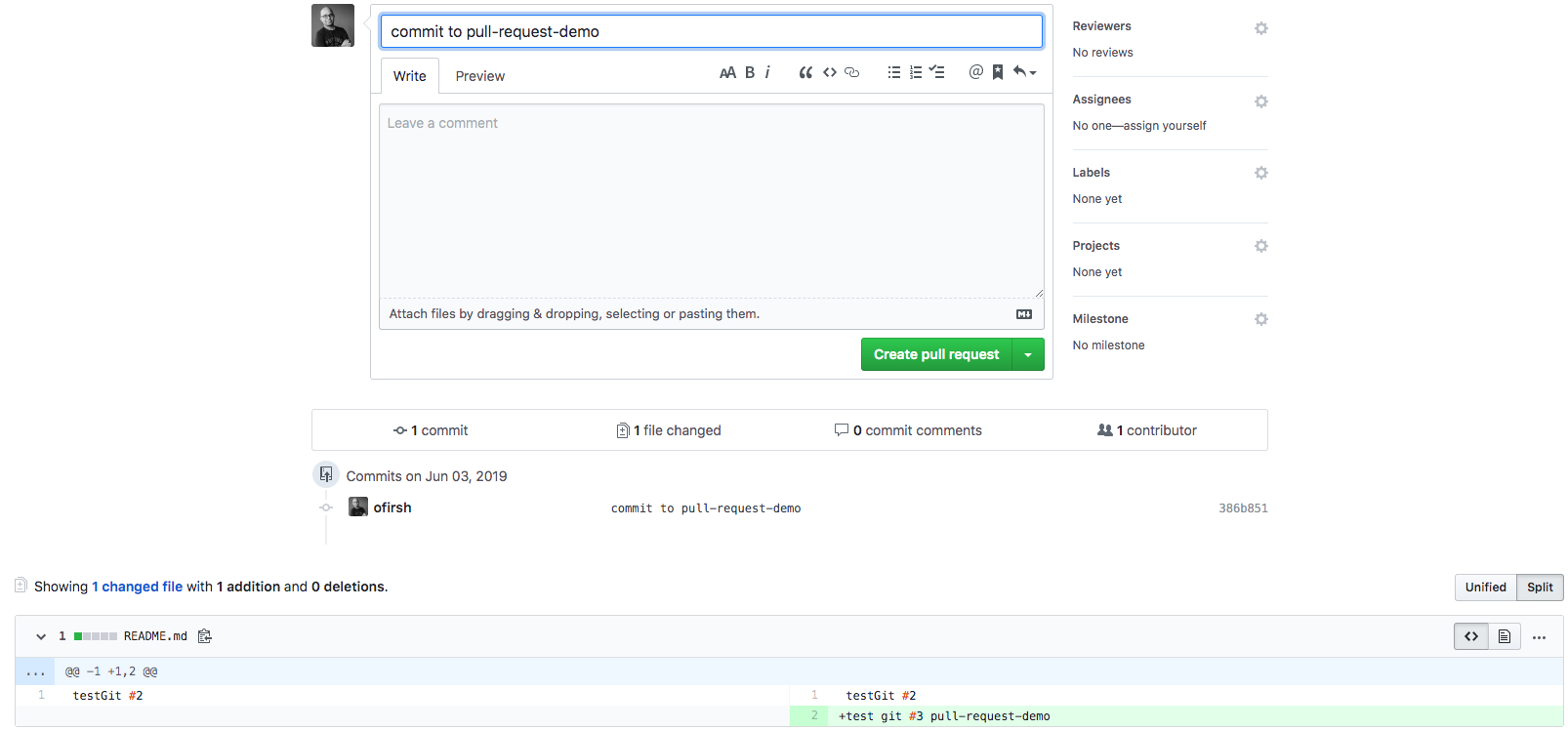
Like most text inputs on GitHub, the description can be written in GitHub Flavored Markdown. Fill it out with a description of your changes. If you especially want a user’s attention in the pull request, you can use the “@username” syntax to mention them (just like on Twitter).
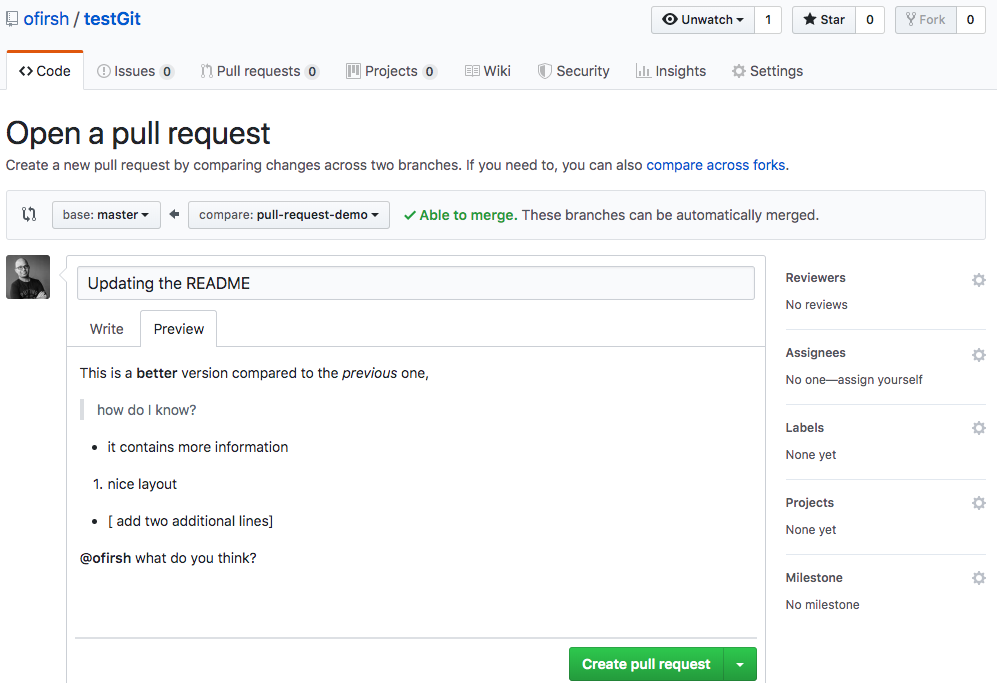
GitHub has a handy guide to writing the perfect pull request that you may want to read before submitting work to other repositories, but for now a description like the one I wrote should be ok. You can see my example pull request here.
Pressing the green “Create pull request”:

And now, pressing the “Merge pull request” button:

Confirm merge:
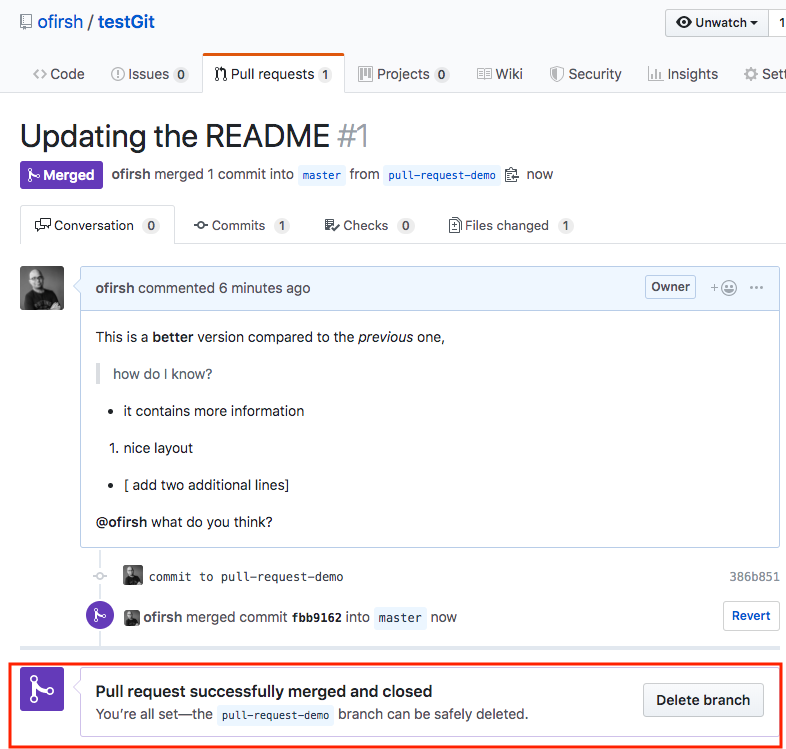
Switching you local repo back to master:
git checkout master

git pull origin master

And now the local repo is pointing to master and contains the merged files.
Enjoy!
BTW please find below a nice Git cheat sheet
References: