What a great symposium! Thank you Dr. Linlin Li, Prof. Ido Dagan, Prof. Noah Smith and the rest of the speakers for the interesting talks and thank you Singapore University of Technology and Design (SUTD) for hosting this event. Here is a quick summary of the first half of the symposium, you can learn more by looking for the papers published by these research groups:
Linlin Li: The text processing engine that powers Alibaba’s business applications
Dr. Linlin Li from Alibaba presented the mission of Alibaba’s NLP group and spoke about AliNLP, a large scale NLP technology platform for the entire Alibaba Eco-system, dealing with data collection and multilingual algorithms for lexical, syntactic, semantic, discourse analysis and distributed representation of text.
Alibaba is also helping to improve the quality of the Electronic Medical Records (EMRs) in China, traditionally done by labour intensive methods.
Ido Dagan: Consolidating Textual Information
Prof. Ido Dagan gave an excellent presentation on Natural Knowledge Consolidating Textual Information. Texts come in large multitudes, such as news story, search results, and product reviews. Search interfaces hasn’t changed much in decades, which make them accessible, but hard to consume. For example, the news tweets illustration in the slide below shows that here is a lot of redundancy and complementary information, so there is a need to consolidate the knowledge within multiple texts.
Generic knowledge representation via structured knowledge graphs and semantic representation are often being used, where both approaches require an expert to annotate the dataset, which is expansive and hard to replicate.
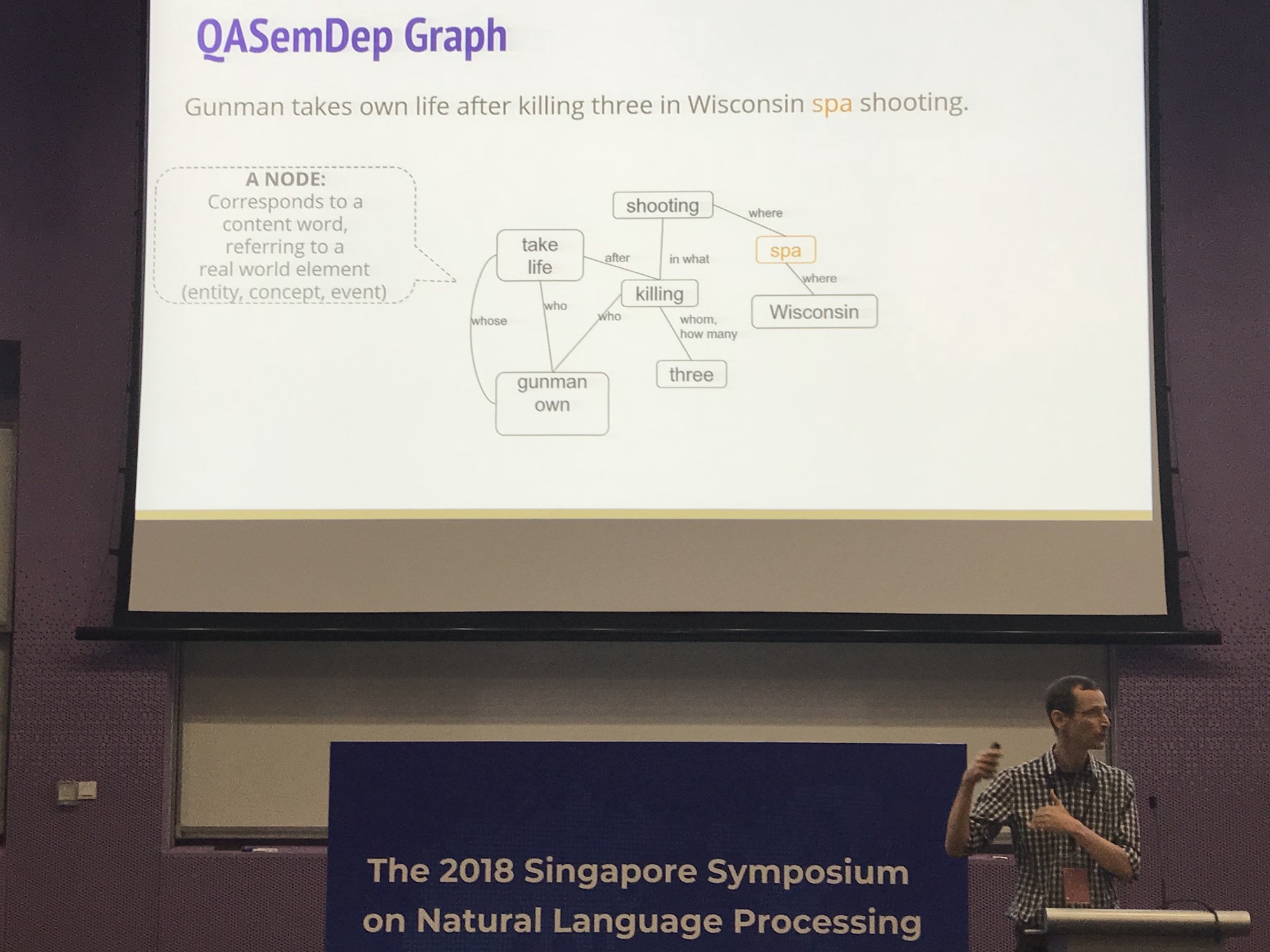
The structure of a single sentence will look like this:
The information can be consolidated across the various data sources via Coreference
To conclude
Noah A. Smith: Syncretizing Structured and Learned Representation
Prof. Noah described new ways to use representation learning for NLP
Some promising results
Prof. Noah presented different approaches to solve backpropagation with structure in the middle, where the intermediate representation is non-differentiable.
See you all the the next conference!