I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
Advanced Vector Extensions (AVX) are extensions to the x86 instruction set architecture for microprocessors from Intel and AMD proposed by Intel in March 2008 and first supported by Intel with the Sandy Bridge processor shipping in Q1 2011 and later on by AMD with the Bulldozer processor shipping in Q3 2011. AVX provides new features, new instructions, and a new coding scheme.
AVX introduces fused multiply-accumulate (FMA) operations, which speed up linear algebra computation, namely dot-product, matrix multiply, convolution, etc. Almost every machine-learning training involves a great deal of these operations, hence will be faster on a CPU that supports AVX and FMA (up to 300%).
We won’t ignore the warning message and we will compile TF from source.
We will start with uninstalling the default version of Tensorflow:
The bazel build command creates an executable named build_pip_package—this is the program that builds the pip package. Run the executable as shown below to build a .whl package in the /tmp/tensorflow_pkg directory.
There are four fundamental elements in the Git Workflow. Working Directory, Staging Area, Local Repository and Remote Repository.
If you consider a file in your Working Directory, it can be in three possible states.
It can be staged. Which means the files with with the updated changes are marked to be committed to the local repository but not yet committed.
It can be modified. Which means the files with the updated changes are not yet stored in the local repository.
It can be committed. Which means that the changes you made to your file are safely stored in the local repository.
git add is a command used to add a file that is in the working directory to the staging area.
git commit is a command used to add all files that are staged to the local repository.
git push is a command used to add all committed files in the local repository to the remote repository. So in the remote repository, all files and changes will be visible to anyone with access to the remote repository.
git fetch is a command used to get files from the remote repository to the local repository but not into the working directory.
git merge is a command used to get the files from the local repository into the working directory.
git pull is command used to get files from the remote repository directly into the working directory. It is equivalent to a git fetch and a git merge .
git --version
git config --global --list
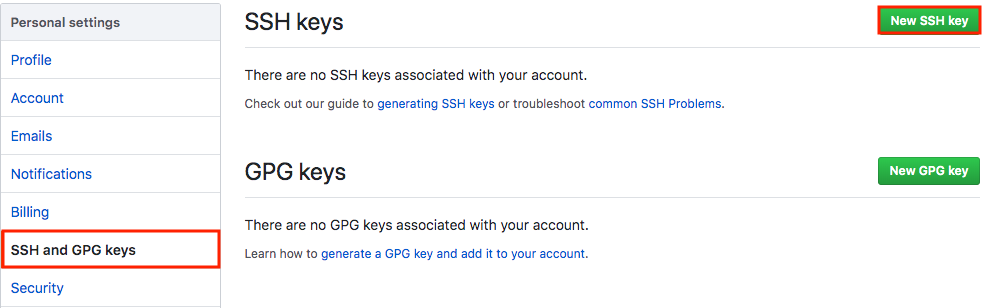
Check your machine for existing SSH keys:
ls -al ~/.ssh
If you already have a SSH key, you can skip the next step of generating a new SSH key
Generating a new SSH key and adding it to the ssh-agent
When adding your SSH key to the agent, use the default macOS ssh-add command. Start the ssh-agent in the background:
Adding a new SSH key to your GitHub account
To add a new SSH key to your GitHub account, copy the SSH key to your clipboard:
pbcopy < ~/.ssh/id_rsa.pub
Copy the In the “Title” field, add a descriptive label for the new key. For example, if you’re using a personal Mac, you might call this key “Personal MacBook Air”.
Paste your key into the “Key” field.
After you’ve set up your SSH key and added it to your GitHub account, you can test your connection:
ssh -T git@github.com
Let’s Git
Create a new repository on GitHub. Follow this link. Now, locate to the folder you want to place under git in your terminal.
echo "# testGit" >> README.md
Now to add the files to the git repository for commit:
git add .
git status
Now to commit files you added to your git repo:
git commit -m "First commit"
git status
Add a remote origin and Push:
Now each time you make changes in your files and save it, it won’t be automatically updated on GitHub. All the changes we made in the file are updated in the local repository.
To add a new remote, use the git remote add command on the terminal, in the directory your repository is stored at.
The git remote add command takes two arguments:
A remote name, for example, origin
A remote URL, for example, https://github.com/user/repo.git
Once you start making changes on your files and you save them, the file won’t match the last version that was committed to git.
Let’s modify README.md to include the following text:
To see the changes you just made:
git diff
Markers for changes
--- a/README.md
+++ b/README.md
These lines are a legend that assigns symbols to each diff input source. In this case, changes from a/README.md are marked with a --- and the changes from b/README.md are marked with the +++ symbol.
Diff chunks
The remaining diff output is a list of diff ‘chunks’. A diff only displays the sections of the file that have changes. In our current example, we only have one chunk as we are working with a simple scenario. Chunks have their own granular output semantics.
Revert back to the last committed version to the Git Repo:
Now you can choose to revert back to the last committed version by entering:
git checkout .
View Commit History:
You can use the git log command to see the history of commit you made to your files:
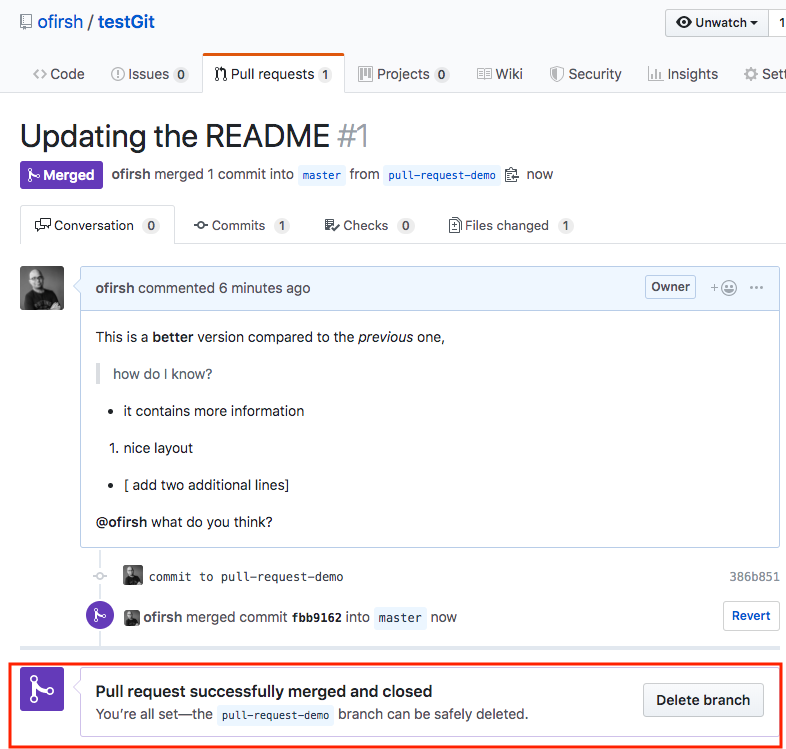
Now you can work on the files you want and commit to changes locally. If you want to push changes to that repository you either have to be added as a collaborator for the repository or you have create something known as pull request. Go and check out how to do one here and give me a pull request with your code file.
So to make sure that changes are reflected on my local copy of the repo:
git pull origin master
Two more useful command:
git fetch
git merge
In the simplest terms, git fetch followed by a git merge equals a git pull. But then why do these exist?
When you use git pull, Git tries to automatically do your work for you. It is context sensitive, so Git will merge any pulled commits into the branch you are currently working in. git pullautomatically merges the commits without letting you review them first.
When you git fetch, Git gathers any commits from the target branch that do not exist in your current branch and stores them in your local repository. However, it does not merge them with your current branch. This is particularly useful if you need to keep your repository up to date, but are working on something that might break if you update your files. To integrate the commits into your master branch, you use git merge.
Pull Request
Pull requests let you tell others about changes you’ve pushed to a GitHub repository. Once a pull request is sent, interested parties can review the set of changes, discuss potential modifications, and even push follow-up commits if necessary.
null
Pull requests are GitHub’s way of modeling that you’ve made commits to a copy of a repository, and you’d like to have them incorporated in someone else’s copy. Usually the way this works is like so:
Lady Ada publishes a repository of code to GitHub.
Brennen uses Lady Ada’s repo, and decides to fix a bug or add a feature.
Brennen forks the repo, which means copying it to his GitHub account, and clones that fork to his computer.
Brennen changes his copy of the repo, makes commits, and pushes them up to GitHub.
Brennen submits a pull request to the original repo, which includes a human-readable description of the changes.
Lady Ada decides whether or not to merge the changes into her copy.
Creating a Pull Request
There are 2 main work flows when dealing with pull requests:
First, we will need to create a branch from the latest commit on master. Make sure your repository is up to date first using
git pull origin master
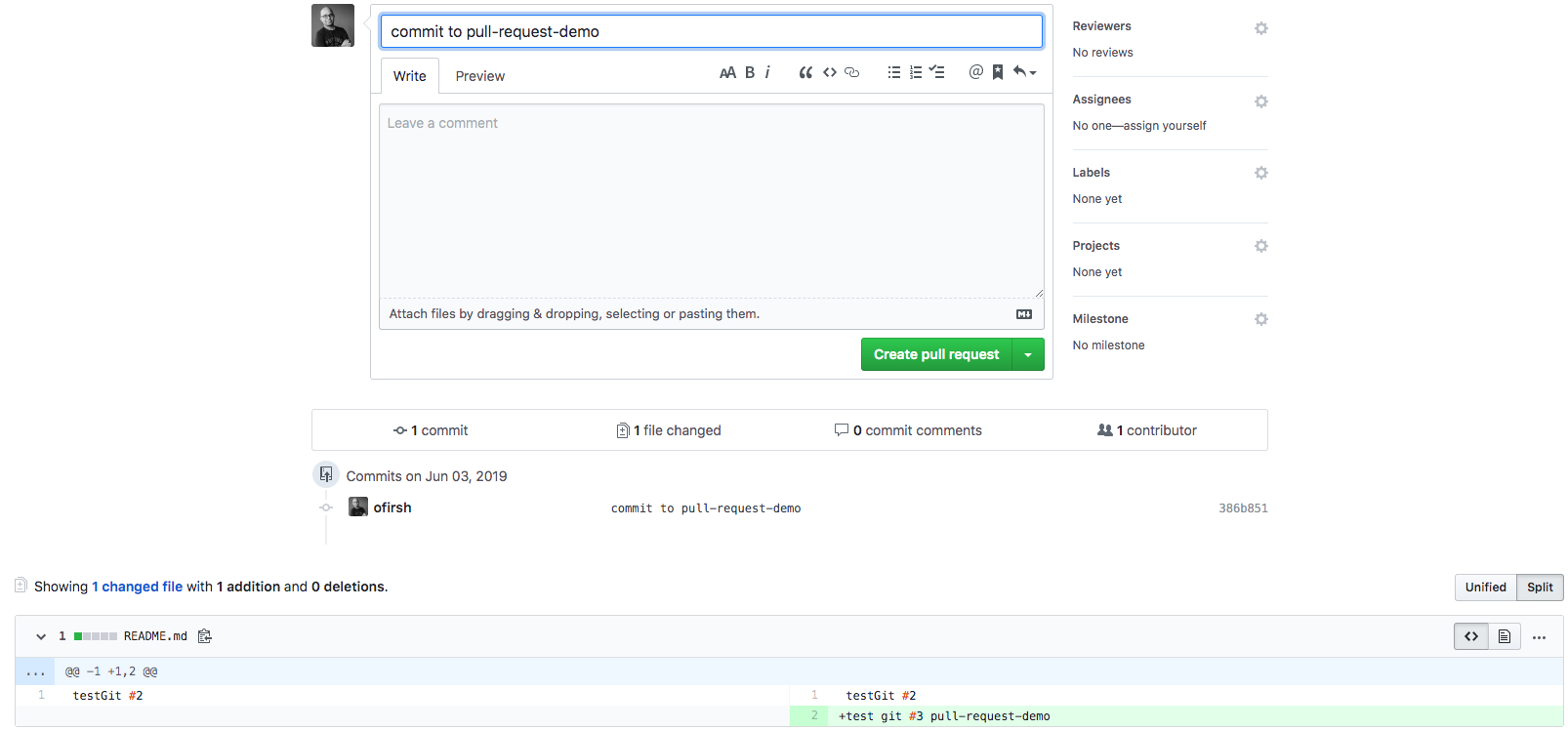
To create a branch, use git checkout -b <new-branch-name> [<base-branch-name>], where base-branch-name is optional and defaults to master. I’m going to create a new branch called pull-request-demo from the master branch and push it to github.
git add README.md
git commit -m 'commit to pull-request-demo'
…and push your new commit back up to your copy of the repo on GitHub:
git push --set-upstream origin pull-request-demo
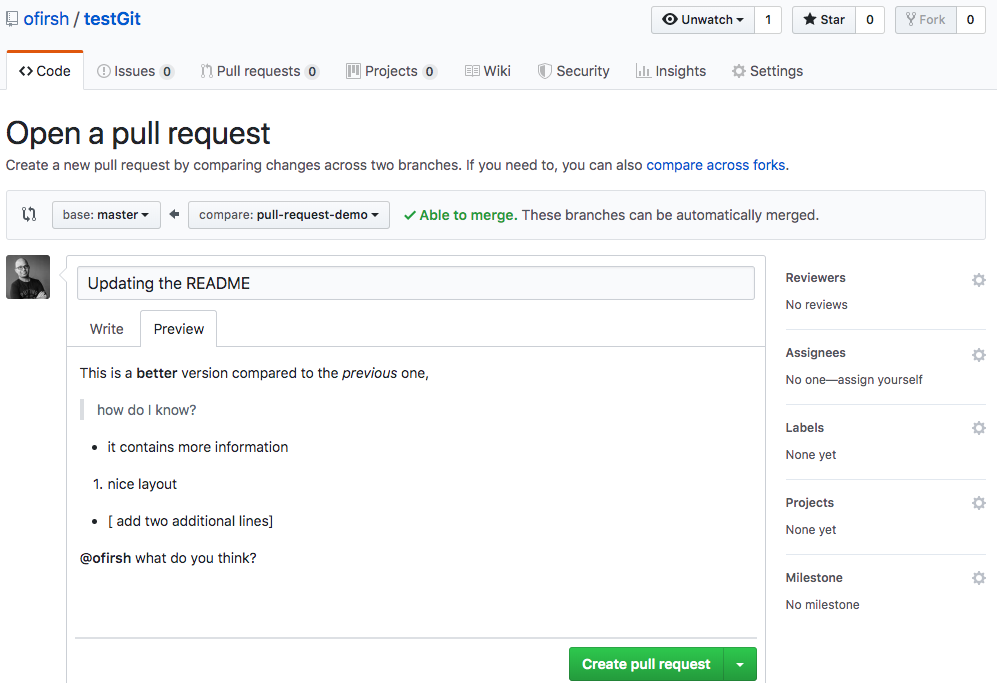
Back to the web interface:
You can press the “Compare”, and now you can create the pull request:
Go ahead and click the big green “Create Pull Request” button. You’ll get a form with space for a title and longer description:
Like most text inputs on GitHub, the description can be written in GitHub Flavored Markdown. Fill it out with a description of your changes. If you especially want a user’s attention in the pull request, you can use the “@username” syntax to mention them (just like on Twitter).
Airflow was started in October 2014 by Maxime Beauchemin at Airbnb. It was open source from the very first commit and officially brought under the Airbnb GitHub and announced in June 2015.
The project joined the Apache Software Foundation’s Incubator program in March 2016 and the Foundation announced Apache Airflow as a Top-Level Project in January 2019.
Apache Airflow is in use at more than 200 organizations, including Adobe, Airbnb, Astronomer, Etsy, Google, ING, Lyft, NYC City Planning, Paypal, Polidea, Qubole, Quizlet, Reddit, Reply, Solita, Square, Twitter, and United Airlines, among others.
Introduction
Airflow is a platform to programmatically author, schedule and monitor workflows.
Use airflow to author workflows as directed acyclic graphs (DAGs) of tasks. The airflow scheduler executes your tasks on an array of workers while following the specified dependencies. Rich command line utilities make performing complex surgeries on DAGs a snap. The rich user interface makes it easy to visualize pipelines running in production, monitor progress, and troubleshoot issues when needed.
When workflows are defined as code, they become more maintainable, versionable, testable, and collaborative.
Workflows
We’ll create a workflow by specifying actions as a Directed Acyclic Graph (DAG) in Python. The tasks of a workflow make up a Graph; the graph is Directed because the tasks are ordered; and we don’t want to get stuck in an eternal loop so the graph also has to be Acyclic.
The figure below shows an example of a DAG:
Installation
pip3 install apache-airflow
airflow version
AIRFLOW_HOME is the directory where you store your DAG definition files and Airflow plugins
mkdir Airflow
export AIRFLOW_HOME=`pwd`/Airflow
Airflow requires a database to be initiated before you can run tasks. If you’re just experimenting and learning Airflow, you can stick with the default SQLite option.
airflow initdb
ls -l Airflow/
The database airflow.db is created
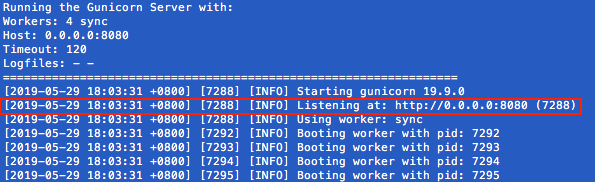
You can start Airflow UI by issuing the following command:
We’ll start by creating a Hello World workflow, which does nothing other then sending “Hello world!” to the log.
Create your dags folder, that is the directory where your DAG definition files will be stored in AIRFLOW_HOME/dags. Inside that directory create a file named hello_world.py:
mkdir dags
Add the following code to dags/hello_world.py
from datetime import datetime
from airflow import DAG
from airflow.operators.dummy_operator import DummyOperator
from airflow.operators.python_operator import PythonOperator
def print_hello():
return 'Hello world!'
dag = DAG('hello_world', description='Simple tutorial DAG',
schedule_interval='0 12 * * *',
start_date=datetime(2019, 5, 29), catchup=False)
dummy_operator = DummyOperator(task_id='dummy_task', retries=3, dag=dag)
hello_operator = PythonOperator(task_id='hello_task', python_callable=print_hello, dag=dag)
dummy_operator >> hello_operator
This file creates a simple DAG with just two operators, the DummyOperator, which does nothing and a PythonOperator which calls the print_hello function when its task is executed.
Running your DAG
Open a second terminal, go to the AIRFLOW_HOME folder and start the Airflow scheduler by issuing :
export AIRFLOW_HOME=`pwd`
airflow scheduler
When you reload the Airflow UI in your browser, you should see your hello_world DAG listed in Airflow UI.
In order to start a DAG Run, first turn the workflow on, then click the Trigger Dag button and finally, click on the Graph View to see the progress of the run.
After clicking the Graph View:
You can reload the graph view until both tasks reach the status Success.
When they are done, you can click on the hello_task and then click View Log.
If everything worked as expected, the log should show a number of lines and among them something like this:
Your first Airflow Operator
Let’s start writing our own Airflow operators. An Operator is an atomic block of workflow logic, which performs a single action. Operators are written as Python classes (subclasses of BaseOperator), where the __init__ function can be used to configure settings for the task and a method named execute is called when the task instance is executed.
Any value that the execute method returns is saved as an Xcom message under the key return_value. We’ll cover this topic later.
The execute method may also raise the AirflowSkipException from airflow.exceptions. In such a case the task instance would transition to the Skipped status.
If another exception is raised, the task will be retried until the maximum number of retries is reached.
Remember that since the execute method can retry many times, it should be idempotent [it can be applied multiple times without changing the result beyond the initial application]
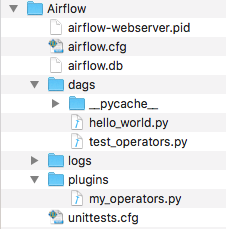
We’ll create your first operator in an Airflow plugin file named plugins/my_operators.py. First create the /plugins directory, then add the my_operators.py file with the following content:
import logging
from airflow.models import BaseOperator
from airflow.plugins_manager import AirflowPlugin
from airflow.utils.decorators import apply_defaults
log = logging.getLogger(__name__)
class MyFirstOperator(BaseOperator):
@apply_defaults
def __init__(self, my_operator_param, *args, **kwargs):
self.operator_param = my_operator_param
super(MyFirstOperator, self).__init__(*args, **kwargs)
def execute(self, context):
log.info("Hello World!")
log.info('operator_param: %s', self.operator_param)
class MyFirstPlugin(AirflowPlugin):
name = "my_first_plugin"
operators = [MyFirstOperator]
In this file we are defining a new operator named MyFirstOperator. Its execute method is very simple, all it does is log “Hello World!” and the value of its own single parameter. The parameter is set in the __init__ function.
We are also defining an Airflow plugin named MyFirstPlugin. By defining a plugin in a file stored in the /plugins directory, we’re providing Airflow the ability to pick up our plugin and all the operators it defines. We’ll be able to import these operators later using the line from airflow.operators import MyFirstOperator.
Now, we’ll need to create a new DAG to test our operator. Create a dags/test_operators.py file and fill it with the following content:
from datetime import datetime
from airflow import DAG
from airflow.operators.dummy_operator import DummyOperator
from airflow.operators import MyFirstOperator
dag = DAG('my_test_dag', description='Another tutorial DAG',
schedule_interval='0 12 * * *',
start_date=datetime(2019, 5, 29), catchup=False)
dummy_task = DummyOperator(task_id='dummy_task', dag=dag)
operator_task = MyFirstOperator(my_operator_param='This is a test.',
task_id='my_first_operator_task', dag=dag)
dummy_task >> operator_task
Here we just created a simple DAG named my_test_dag with a DummyOperator task and another task using our new MyFirstOperator. Notice how we pass the configuration value for my_operator_param here during DAG definition.
At this stage your source tree looks like this:
To test your new operator, you should stop (CTRL-C) and restart your Airflow web server and scheduler. Afterwards, go back to the Airflow UI, turn on the my_test_dag DAG and trigger a run. Take a look at the logs for my_first_operator_task.
Your first Airflow Sensor
An Airflow Sensor is a special type of Operator, typically used to monitor a long running task on another system.
To create a Sensor, we define a subclass of BaseSensorOperator and override its poke function. The poke function will be called over and over every poke_interval seconds until one of the following happens:
poke returns True – if it returns False it will be called again.
poke raises an AirflowSkipException from airflow.exceptions – the Sensor task instance’s status will be set to Skipped.
poke raises another exception, in which case it will be retried until the maximum number of retries is reached.
As an example, SqlSensor runs a sql statement until a criteria is met, HdfsSensor waits for a file or folder to land in HDFS, S3KeySensor waits for a key (a file-like instance on S3) to be present in a S3 bucket), S3PrefixSensor waits for a prefix to exist and HttpSensor executes a HTTP get statement and returns False on failure.
To add a new Sensor to your my_operators.py file, add the following code:
from datetime import datetime
from airflow.operators.sensors import BaseSensorOperator
class MyFirstSensor(BaseSensorOperator):
@apply_defaults
def __init__(self, *args, **kwargs):
super(MyFirstSensor, self).__init__(*args, **kwargs)
def poke(self, context):
current_minute = datetime.now().minute
if current_minute % 3 != 0:
log.info("Current minute (%s) not is divisible by 3, sensor will retry.", current_minute)
return False
log.info("Current minute (%s) is divisible by 3, sensor finishing.", current_minute)
return True
Here we created a very simple sensor, which will wait until the the current minute is a number divisible by 3. When this happens, the sensor’s condition will be satisfied and it will exit. This is a contrived example, in a real case you would probably check something more unpredictable than just the time.
Remember to also change the plugin class, to add the new sensor to the operators it exports:
class MyFirstPlugin(AirflowPlugin):
name = "my_first_plugin"
operators = [MyFirstOperator, MyFirstSensor]
The final my_operators.py file is:
import logging
from airflow.models import BaseOperator
from airflow.plugins_manager import AirflowPlugin
from airflow.utils.decorators import apply_defaults
from datetime import datetime
from airflow.operators.sensors import BaseSensorOperator
log = logging.getLogger(__name__)
class MyFirstOperator(BaseOperator):
@apply_defaults
def __init__(self, my_operator_param, *args, **kwargs):
self.operator_param = my_operator_param
super(MyFirstOperator, self).__init__(*args, **kwargs)
def execute(self, context):
log.info("Hello World!")
log.info('operator_param: %s', self.operator_param)
class MyFirstSensor(BaseSensorOperator):
@apply_defaults
def __init__(self, *args, **kwargs):
super(MyFirstSensor, self).__init__(*args, **kwargs)
def poke(self, context):
current_minute = datetime.now().minute
if current_minute % 3 != 0:
log.info("Current minute (%s) not is divisible by 3, sensor will retry.", current_minute)
return False
log.info("Current minute (%s) is divisible by 3, sensor finishing.", current_minute)
return True
class MyFirstPlugin(AirflowPlugin):
name = "my_first_plugin"
operators = [MyFirstOperator, MyFirstSensor]
You can now place the operator in your DAG, so the new test_operators.py file looks like:
from datetime import datetime
from airflow import DAG
from airflow.operators.dummy_operator import DummyOperator
from airflow.operators import MyFirstOperator, MyFirstSensor
dag = DAG('my_test_dag', description='Another tutorial DAG',
schedule_interval='0 12 * * *',
start_date=datetime(2019, 5, 29), catchup=False)
dummy_task = DummyOperator(task_id='dummy_task', dag=dag)
sensor_task = MyFirstSensor(task_id='my_sensor_task', poke_interval=30, dag=dag)
operator_task = MyFirstOperator(my_operator_param='This is a test.',
task_id='my_first_operator_task', dag=dag)
dummy_task >> sensor_task >> operator_task
Restart your webserver and scheduler and try out your new workflow. The Graph View looks like:
If you click View log of the my_sensor_task task, you should see something similar to this: