At the first day of the Strata+Hadoop, Maosong Fu, Tech Lead for Realtime Compute at Twitter shared some details on Twitter’s real-time stack

There are many industries where optimizing in real-time can have a large impact on overall business performance, leading to instant benefits in customer acquisition, retention, and marketing.

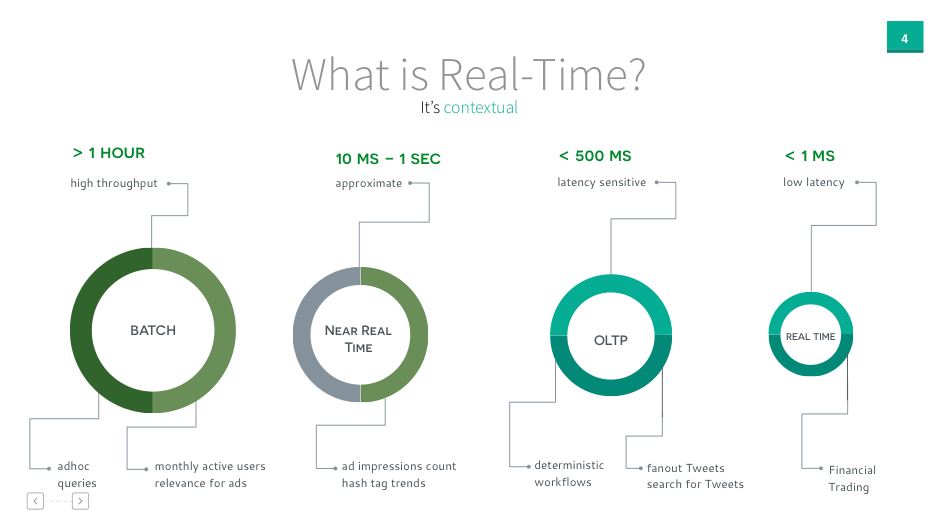
But how fast is real-time? It depends on the context, whether it’s financial trading, tweeting, ad impression count or monthly dashboard.
Earlier Twitter messaging stack
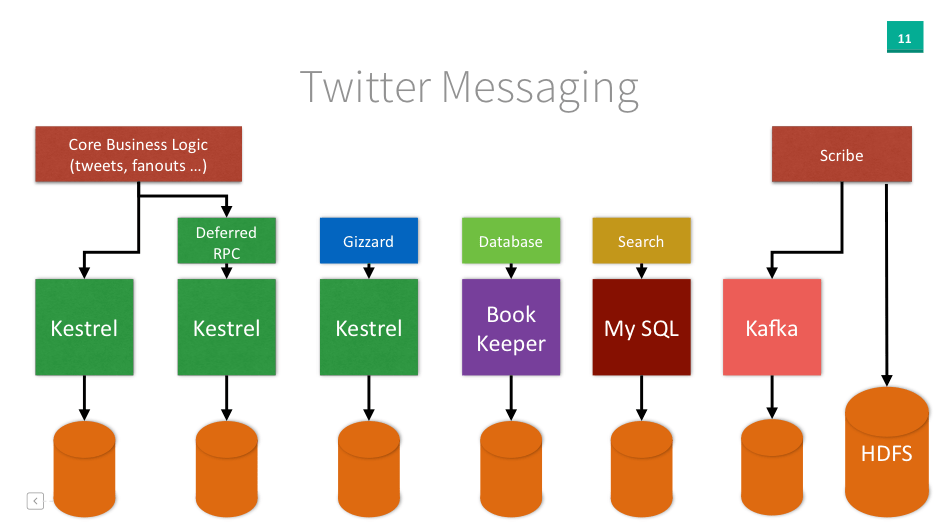
Kestrel is a message queue server we use to asynchronously connect many of the services and functions underlying the Twitter product. For example, when users update, any tweets destined for SMS delivery are queued in a Kestrel; the SMS service then reads tweets from this queue and communicates with the SMS carriers for delivery to phones. This implementation isolates the behavior of SMS delivery from the behavior of the rest of the system, making SMS delivery easier to operate, maintain, and scale independently.
Scribe is a server for aggregating log data streamed in real time from a large number of servers.
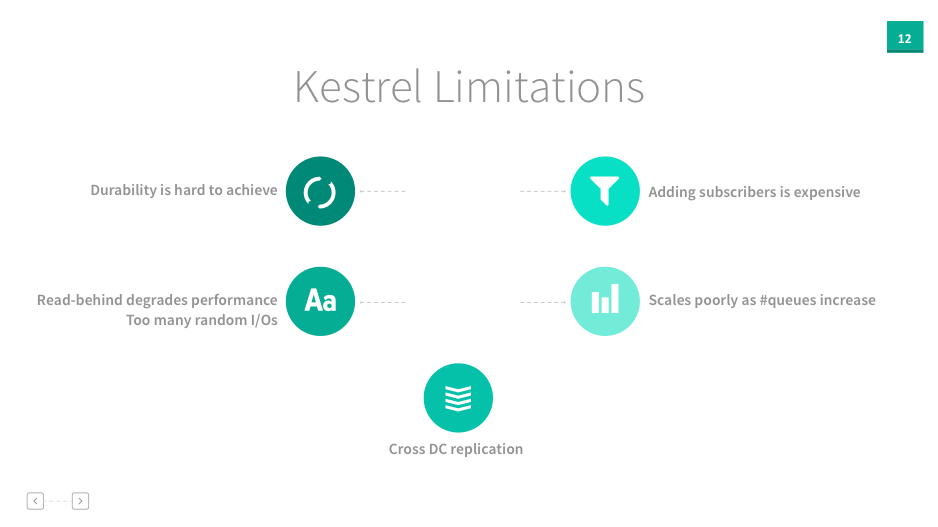
Some of Kestrel’s limitations are listed in the below:
- Durability is hard to achieve
- Read-behind degrades performance
- Adding subscribers is expensive
- Scales poorly as number of queues increase
- Cross DC replication
From Twitter Github:
We’ve deprecated Kestrel because internally we’ve shifted our attention to an alternative project based on DistributedLog, and we no longer have the resources to contribute fixes or accept pull requests. While Kestrel is a great solution up to a certain point (simple, fast, durable, and easy to deploy), it hasn’t been able to cope with Twitter’s massive scale (in terms of number of tenants, QPS, operability, diversity of workloads etc.) or operating environment (an Aurora cluster without persistent storage).
Kafka™ is used for building real-time data pipelines and streaming apps. It is horizontally scalable, fault-tolerant, wicked fast, and runs in production in thousands of companies.
Kafka relies on file system page cache with performance degradation when subscribers fall behind – too many random I/O

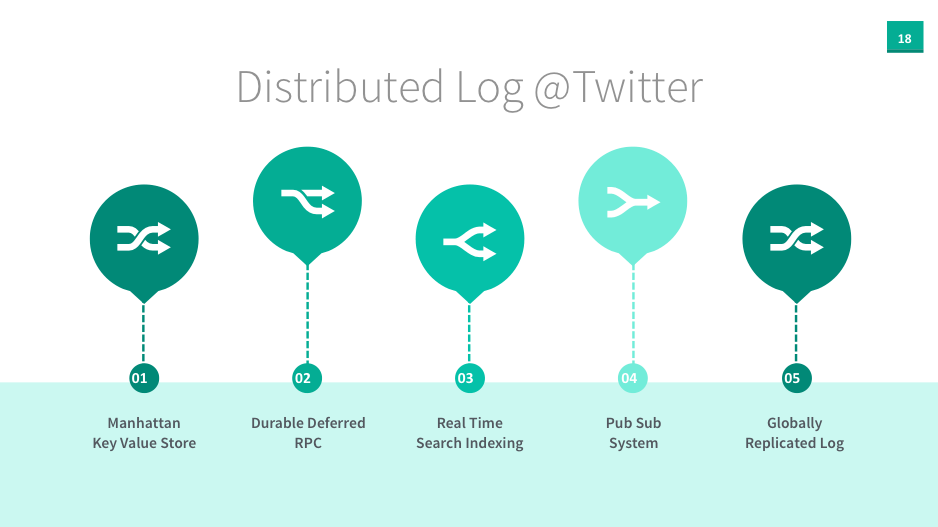
Rethinking messaging

Apache DistributedLog (DL) is a high-throughput, low-latency replicated log service, offering durability, replication and strong consistency as essentials for building reliable real-time applications.

Event Bus

Features of DistributedLog at Twitter:
High Performance
DL is able to provide milliseconds latency on durable writes with a large number of concurrent logs, and handle high volume reads and writes per second from thousands of clients.
Durable and Consistent
Messages are persisted on disk and replicated to store multiple copies to prevent data loss. They are guaranteed to be consistent among writers and readers in terms of strict ordering.
Efficient Fan-in and Fan-out
DL provides an efficient service layer that is optimized for running in a multi- tenant datacenter environment such as Mesos or Yarn. The service layer is able to support large scale writes (fan-in) and reads (fan-out).
Various Workloads
DL supports various workloads from latency-sensitive online transaction processing (OLTP) applications (e.g. WAL for distributed database and in-memory replicated state machines), real-time stream ingestion and computing, to analytical processing.
Multi Tenant
To support a large number of logs for multi-tenants, DL is designed for I/O isolation in real-world workloads.
Layered Architecture
DL has a modern layered architecture design, which separates the stateless service tier from the stateful storage tier. To support large scale writes (fan- in) and reads (fan-out), DL allows scaling storage independent of scaling CPU and memory.
Storm was no longer able to support Twitter’s requirements and although Twitter improved Storm’s performance eventually Twitter decided to develop Heron.
Heron is a realtime, distributed, fault-tolerant stream processing engine from Twitter. Heron is built with a wide array of architectural improvements that contribute to high efficiency gains.

Heron has powered all realtime analytics with varied use cases at Twitter since 2014. Incident reports dropped by an order of magnitude demonstrating proven reliability and scalability
Heron is in production for the last 3 years, reducing hardware requirements by 3x. Heron is highly scalable both in the ability to execute large number of components for each topology and the ability to launch and track large numbers of topologies.

Lambda architecture is a data-processing architecture designed to handle massive quantities of data by taking advantage of both batch– and stream-processing methods. This approach to architecture attempts to balance latency, throughput, and fault-tolerance by using batch processing to provide comprehensive and accurate views of batch data, while simultaneously using real-time stream processing to provide views of online data. The two view outputs may be joined before presentation.
The way this works is that an immutable sequence of records is captured and fed into a batch system and a stream processing system in parallel. You implement your transformation logic twice, once in the batch system and once in the stream processing system. You stitch together the results from both systems at query time to produce a complete answer.
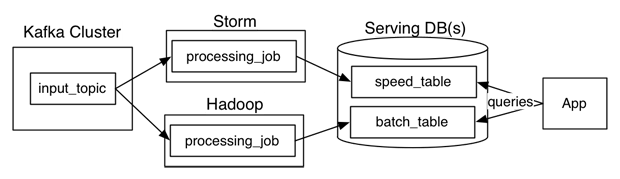
Lambda Architecture: the good

The problem with the Lambda Architecture is that maintaining code that needs to produce the same result in two complex distributed systems is exactly as painful as it seems like it would be.

Summingbird to the Rescue! Summingbird is a library that lets you write MapReduce programs that look like native Scala or Java collection transformations and execute them on a number of well-known distributed MapReduce platforms, including Storm and Scalding.

Curious to Learn More?

Interested in Heron?
Code at: https://github.com/twitter/heron
http://twitter.github.io/heron/

