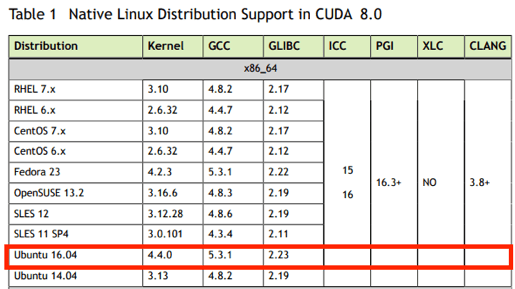
Multiple Imputation by Chained Equations (MICE)

As every data scientist will witness, it is rarely that your data is 100% complete. We are often taught to “ignore” missing data. In practice, however, ignoring or inappropriately handling the missing data may lead to biased estimates, incorrect standard errors and incorrect inferences.
But first we need to think about what led to this missing data, or what was the mechanism by which some values were missing and some were observed?
There are three different mechanisms to describe what led to the missing values:
- Missing Completely At Random (MCAR): the missing observations are just a random subset of all observations, so there are no systematic differences between the missing and observed data. In this case, analysis using only complete cases will not be biased, but may have lower power.
- Missing At Random (MAR): there might be systematic differences between the missing and observed data, but these can be entirely explained by other observed variables. For example, a case where you observe gender and you see that women are more likely to respond than men. Including a lot of predictors in the imputation model can make this assumption more plausible.
- Not Missing At Random (NMAR): the probability of a variable being missing might depend on itself on other unobserved values. For example, the probability of someone reporting their income depends on what their income is.
MICE operates under the assumption that given the variables used in the imputation procedure, the missing data are Missing At Random (MAR), which means that the probability that a value is missing depends only on observed values and not on unobserved values
Multiple imputation by chained equations (MICE) has emerged in the statistical literature as one principled method of addressing missing data. Creating multiple imputations, as opposed to single imputations, accounts for the statistical uncertainty in the imputations. In addition, the chained equations approach is very flexible and can handle variables of varying types (e.g., continuous or binary) as well as complexities such as bounds.
The chained equation process can be broken down into the following general steps:
- Step 1: A simple imputation, such as imputing the mean, is performed for every missing value in the dataset. These mean imputations can be thought of as “place holders.”
- Step 2: Start Step 2 with the variable with the fewest number of missing values. The “place holder” mean imputations for one variable (“var”) are set back to missing.
- Step 3: “var” is the dependent variable in a regression model and all the other variables are independent variables in the regression model.
- Step 4: The missing values for “var” are then replaced with predictions (imputations) from the regression model. When “var” is subsequently used as an independent variable in the regression models for other variables, both the observed and these imputed values will be used.
- Step 5: Moving on to the next variable with the next fewest missing values, steps 2–4 are then repeated for each variable that has missing data. The cycling through each of the variables constitutes one iteration or “cycle.” At the end of one cycle all of the missing values have been replaced with predictions from regressions that reflect the relationships observed in the data.
- Step 6: Steps 2 through 4 are repeated for a number of cycles, with the imputations being updated at each cycle. The idea is that by the end of the cycles the distribution of the parameters governing the imputations (e.g., the coefficients in the regression models) should have converged in the sense of becoming stable.
To make the chained equation approach more concrete, imagine a simple example where we have 3 variables in our dataset: age, income, and gender, and all 3 have at least some missing values. I created this animation as a way to visualize the details of the following example, so let’s get started.

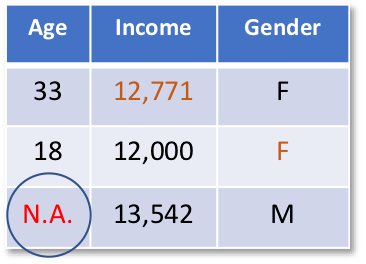
The initial dataset is given below, where missing values are marked as N.A.

In step 1 of the MICE process, each variable would first be imputed using, e.g., mean imputation, temporarily setting any missing value equal to the mean observed value for that variable.

Then in the next step the imputed mean values of age would be set back to missing (N.A).
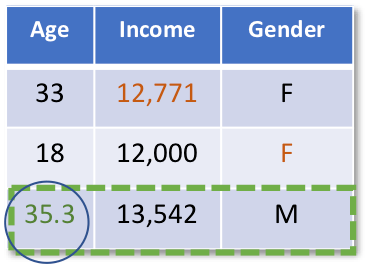
In the next step Bayesian linear regression of age predicted by income and gender would be run using all cases where age was observed.

In the next step, prediction of the missing age value would be obtained from that regression equation and imputed. At this point, age does not have any missingness.
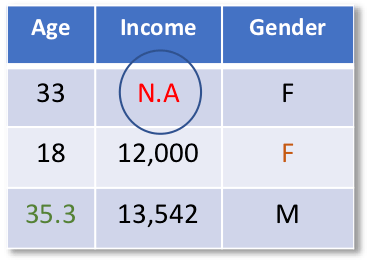
The previous steps would then be repeated for the income variable. The originally missing values of income would be set back to missing (N.A).
A linear regression of income predicted by age and gender would be run using all cases with income observed.
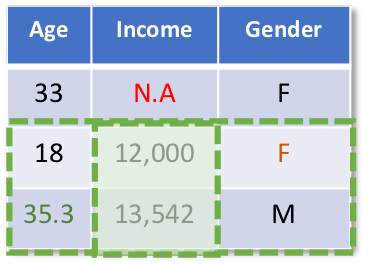
Imputations (predictions) would be obtained from that regression equation for the missing income value.
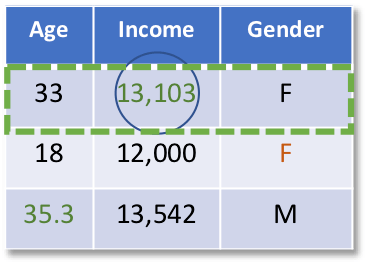
Then, the previous steps would again be repeated for the variable gender. The originally missing values of gender would be set back to missing and a logistic regression of gender on age and income would be run using all cases with gender observed. Predictions from that logistic regression model would be used to impute the missing gender values.

This entire process of iterating through the three variables would be repeated until some measure of convergence, where the imputations are stable; the observed data and the final set of imputed values would then constitute one “complete” data set.
We then repeat this whole process multiple times in order to get multiple imputations.
* Let’s connect on Twitter (@ofirdi), LinkedIn or my Blog
Resources
What is the difference between missing completely at random and missing at random? Bhaskaran et al https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4121561/
A Multivariate Technique for Multiply Imputing Missing Values Using a Sequence of Regression Models, E. Raghunathan et al http://www.statcan.gc.ca/pub/12-001-x/2001001/article/5857-eng.pdf
Multiple Imputation by Chained Equations: What is it and how does it work? Azur et al https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3074241/
Recent Advances in missing Data Methods: Imputation and Weighting – Elizabeth Stuart https://www.youtube.com/watch?v=xnQ17bbSeEk























































{kind=link}
{kind=link}