Many companies are interested in turning their data assets into products and services. It’s not limited anymore to online firms like LinkedIn or Facebook, but there is a variety of companies in offline industries (GM, Apple etc) who have started to develop products and services based on analytics.
But how do you succeed at developing and launching data products?
I would like to suggest a framework building on the idea of Lean Startup and the Minimum Viable Product (MVP), to support the rapid modelling and development of innovative data products. These principles can be applied when launching a new tech start-up, starting a small business, or when starting a new initiative within a large corporation.

A minimum viable product has just those core features that allow the product to be deployed, and no more. The product is typically deployed to a subset of possible customers, such as early adopters that are thought to be more forgiving, more likely to give feedback, and able to grasp a product vision from an early prototype or marketing information
http://en.wikipedia.org/wiki/Minimum_viable_product
Some of the benefits of prototyping and developing MVP:
1. You can get valuable feedback from the users early in the project.
2. Different stakeholders can compare if the model matches the specification.
3. It allows the model developer some insight into the accuracy of initial project estimates and whether the deadlines and milestones proposed can be successfully met.
Our fully functional model will look like that:

Before we dive into the details, feel free to play around with the prototype and get familiar with the model http://benefits.shinyapps.io/BenefitsSimulation/
Ready to go?
Let’s go through the different stages of the process, following a simple example and using R and Shiny for modelling and prototyping. I’ve also published the code in my github repository http://github.com/ofirsh/BenefitsSimulation , feel free to fork it and to play with it.
Ideas
This is where your creativity should kick in! What problem do you try to solve by using data?
Are you aware of a gap in the industry that you currently work in?
Let’s follow a simple example:
Effective employee benefits will significantly reduce staff turnover and companies with the most effective benefits are using them to influence the behavior of their staff and their bottom line, as opposed to simply being competitive
How can you find this optimal point, balancing between the increasing cost of employee benefits and the need to retain staff and reduce staff turnover?
Model
We will assume a (simplified) model that links the attrition rates to the benefits provided to the employee.
I know, it’s simplified. I’m also aware that there are many other relevant parameters in a real-life scenario.
But it’s just an example, so let’s move on.

Our simplified model depends on the following parameters:
- Number of Employees
- Benefits Saturation ($): we assume a linear dependency between the attrition rate and the benefits provided by the company. As the benefits increase, attrition rate drops, to 0% attrition at the point of Benefits Saturation. Any increase of benefits above the Benefits Saturation point will not have an impact on the attrition rates.
- Benefits ($): benefits provided by the company
- Max Attrition (%): maximal attrition rates at lowest benefits (100$)
- Training Period (months): number of months required to train a new employee
- Salary ($)
This model demonstrates the balance between increasing the benefits and the overall cost, and reducing the attrition rate and the associated cost related to hiring and training of new staff.
We will use R to implement our model:
R is an open-source software environment for statistical computing and graphics. The R language is widely used among statisticians and data miners for developing statistical software and data analysis.
http://en.wikipedia.org/wiki/R_%28programming_language%29
We will use R-Studio, a powerful and productive user interface for R. It’s free and open source, and works great on Windows, Mac, and Linux.
Let’s create a file named server.R and write some code. You can find the full source code in my github repository:
Cutoff is a function that models the attrition vs. benefits, where cutoffx is the value of Benefits Saturation:
cutoff <- function(minx, maxx,maxy,cutoffx,x)
{
ysat <- (x>=cutoffx)*0
slope <- ( 0 – maxy ) / ( cutoffx – minx )
yslope <- (maxy + (x-minx)*slope)*(x
return(ysat + yslope)
}
Calculating the different cost components:
benefitsCost <- input$numberee * input$benefits
attritionCost <- input$salary * nTrainingMonths * input$numberee * (currentAttrition / 100)
overallCost <- benefitsCost + attritionCost
The value of the variables starting with input$ is retrieved from the sliding bars, which are part of the User Interface (UI):
When changing the value of the slider named “Number Of Empolyees” from a value of 200 to a value of 300, the value of the variable input$numberee will change from 200 to 300 accordingly.
Benefits is a sequence of 20 numbers from 100 to 500, covering the range of benefits:
benefits <- round(seq(from = 100, to = 500, length.out = 20))
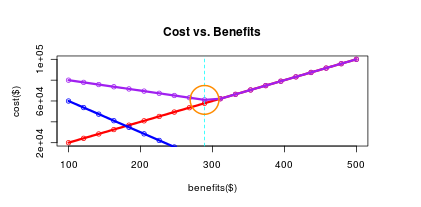
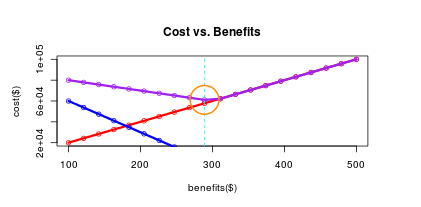
Let’s plot the benefits cost, the attrition cost and the overall cost as a function of the benefits:
The different cost components are calculated below:
benefitsCostV <- input$numberee * benefits
attritionCostV <- input$salary * nTrainingMonths * input$numberee * (attrition / 100) totalCostV <- benefitsCostV + attritionCostV
And now we can plot the different cost components:
plot(benefitsCostV ~ benefits,col = “red”, main = “Cost vs. Benefits”, xlab = “benefits($)”, ylab = “cost($)”)
lines(benefits,benefitsCostV, col = “red”, lwd = 3)
points(benefits,attritionCostV, col = “blue”)
lines(benefits,attritionCostV, col = “blue”,lwd = 3)
points(benefits,totalCostV, col = “purple”)
lines(benefits,totalCostV, col = “purple”,lwd = 3)
Let’s find the minimal cost, and draw a nice orange circle around this optimal point:
minBenefitsIndex <- which.min(totalCostV)
minBenefits <- benefits[minBenefitsIndex]
minBenefitsCost <- totalCostV[minBenefitsIndex]
abline(v=minBenefits,col = “cyan”, lty = “dashed”, lwd = 1)
symbols(minBenefits,minBenefitsCost,circles=20, fg = “darkorange”, inches = FALSE, add=TRUE, lwd = 2)
Tip: Don’t spend too much time on writing the perfect R code; your model might change a lot once your stakeholders will provide their feedback.
Prototype
Shiny is web application framework for R that will turn your analyses into interactive web applications.
Let’s install Shiny and import the library functions:
install.packages(“shiny”)
library(shiny)
Once we have the model in place, we will create the user interface and link it back to the model.
Create a new file named ui.R with the User Interface (UI) elements.
For example, let’s write some text:
titlePanel(“Cost Optimization (Benefits and Talent) – Simulation”),
h5(“This interactive application simulates the impact of multiple …..
And let’s add a slider:
sliderInput(“numberee”,
“Number of Enployees:”,
min = 100,
max = 1000,
value = 200,
step = 100),
The inputId of the slider (numberee) is linking the value of the UI control (number of Employees) to the server side computation engine.
Create a Shiny account, copy-paste the token and a secret to the command line and execute in R-Studio:
shinyapps::setAccountInfo(name=’benefits’, token=’xxxx’, secret=’yyyy’)
And, deploy your code to the Shiny server:
deployApp()
Your prototype is live! http://benefits.shinyapps.io/BenefitsSimulation/
Send the URL to your stakeholders and collect their feedback. Iterate quickly and improve the model and the user interface.
Product
Once your stakeholders are happy with your prototype, it’s time to move on to the next stage and develop your data product.
The good news is that at this stage you should have a pretty good understanding of the requirements and the priorities, based on the feedback provided by your stakeholders.
It’s also the perfect time for you (or for your product development group) to focus more on hosting, architecture, design, the Software Development Life-cycle (SDLC), quality assurance, release management and more.
There are different technologies to consider when developing data products, which I will cover in future posts.
For now I will just mention an interesting option, where you can reuse your server-side R code. Using yhat you can expose your server-side R functionality via a set of web services, and consume these services from a client-side JavaScript libraries, like d3js.
Comments, questions?
Let me know.







 Right Whale Recognition
Right Whale Recognition