Judea Pearl, a pioneering figure in artificial intelligence, argues that AI has been stuck in a decades-long rut. His prescription for progress? Teach machines to understand the question why.
All the impressive achievements of deep learning amount to just curve fitting
Judea Pearl
Yoshua Bengio added in a recent interview
Now, Bengio says deep learning needs to be fixed. He believes it won’t realize its full potential, and won’t deliver a true AI revolution, until it can go beyond pattern recognition and learn more about cause and effect. In other words, he says, deep learning needs to start asking why things happen.
https://www.wired.com/story/ai-pioneer-algorithms-understand-why/
When we look at observational metrics, our Machine Learning models are doing great predicting a certain outcome given a treatment, but they are good exactly at that and not at the counterfactual – what would have been the outcome given no treatment
Causal Inference by Miguel Hernán and James Robins provides a great introduction to causal inference. You can download latest draft from their website:

The book is divided in three parts of increasing difficulty: Part I is about causal inference without models (i.e., nonparametric identification of causal effects), Part II is about causal inference with models (i.e., estimation of causal effects with parametric models), and Part III is about causal inference from complex longitudinal data (i.e., estimation of causal effects of time-varying treatments).
Here are the top four reasons of why I think it’s a great book:
Detailed introduction to the key concepts including many examples
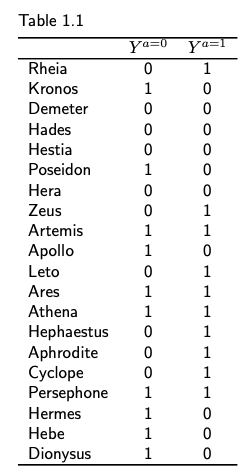
The first four chapters (a definition of causal effect, randomised experiments, observational studies and effect modification) cover key concepts such as potential outcomes (the outcome variable that would have been observed under a certain treatment value), individual and average causal effects, randomisation, identifiability conditions, exchangeability, positivity and consistency. You will get to know Zeus’s extended family, with many examples covering their various health conditions and treatment options. As an example, table 1.1 shows the counterfactual outcomes (die or not) under both treatment (a = 1 a heart transplant) and no treatment (a = 0). Providing practical examples along with the definition helps cement the learning by identifying the key attributes associated with the concept.
Practical approach
Starting from the introduction, the authors are quite clear about their goals
Importantly, this is not a philosophy book. We remain agnostic about metaphysical concepts like causality and cause. Rather, we focus on the identification and estimation of causal effects in populations, that is, numerical quantities that measure changes in the distribution of an outcome under different interventions. For example, we discuss how to estimate
INTRODUCTION: TOWARDS LESS CASUAL CAUSAL INFERENCES
in patients with serious heart failure if they received a heart transplant versus if they did not receive a heart transplant. Our main goal is to help decision makers make better decisions
On top of it, the book comes with a large number of code example in both R and Python, covering the first two part including chapters 11-17. It would be great to see additional code examples covering part three (causal inference from complex longitudinal data).
You should start with reading the book, and on parallel fire-up
jupyter notebook

and start playing with the code

The validity of causal inferences models
The authors discuss a large number of non-parametric and parametric techniques and algorithms to calculate causal effects. But they keep reminding us that all of these techniques rely on untestable assumptions and on expert knowledge. As an example:
Unfortunately, no matter how many variables are included in L, there is no way to test that the assumption (conditional exchangeability) is correct, which makes causal inference from observational data a risky task. The validity of causal inferences requires that the investigators’ expert knowledge is correct
and
Causal inference generally requires expert knowledge and untestable assumptions about the causal network linking treatment, outcome, and other variables.
A (geeky) sense of humor
Technical books tend to be concise and dry, telling an anecdote or adding a joke can make difficult content more enjoyable and understandable.
As an example, when discussing the potential outcomes of the heart transplant treatment in Zeus’s extended family, here is how the authors introduced the issue of sampling variability:
At this point you could complain that our procedure to compute effect measures is somewhat implausible. Not only did we ignore the well known fact that the immortal Zeus cannot die, but more to the point – our population in Table 1.1 had only 20 individuals.
Chapter 1.4
As another example, chapter 7 introduces the topic of confounding variables using an observational study which is designed to answer the causal question “does one’s looking up to the sky make other pedestrians look up too?”. The plot develops and new details are being shared in chapters 8 (selection bias), chapter 9 (measurement bias) and chapter 10 (random variability), till the authors announce the following
Do not worry. No more chapter introductions around the effect of your looking up on other people’s looking up. We squeezed that example well beyond what seemed possible
Chapter 11
I hope that you will find this book useful and that you will enjoy learning about Causal Inference as much as I did!
